No, I Will Not Call This Diogenes GAN-terns

Project Overview
The goal of the project was to create a Generative Adversarial Network (GAN) that would produce visually interesting images. A unique wildflower native to Northern California, the Diogenes Lantern, was selected for the training set based on the pleasing geometric structures and vibrant yellow color.

While reliant on deep-learning techniques, this project differed in several key factors from the normal implementation of these methodologies. The first is that the end goal was not necessarily to create the most convincing replication of the training set, but rather to create something within the artistic realm while capturing the underlying essence of the flower. The second, and related variance, is that because the goal was not to necessarily recreate indistinguishable images, optimization and hyperparameter tuning were not required.
Machine Learning background
If you are unfamiliar with the concepts of neural networks or GANs please feel free to read the following articles:
Data Collection and Augmentation
A total of 172 unique images were scraped using Google image search. This is far fewer than is traditionally leveraged for these types of implementations, especially given the variety of angles, proximity, and backgrounds within the data set. However, due to the stated goal of only needing to create visually interesting images, this is acceptable.
Digital augmentation was implemented in order to supplement the dataset and artificially inject variations into the collected images. Zoom, croping, rotation, stretch/skew, and limited color balance changes were randomly applied to create additional images.
Hardware and Software
The networks were trained on a Linux machine-learning server leveraging an NVIDIA GeForce 1060 GPU. The server has an Intel core I5 processor and 16 GB of RAM.
The code for the networks was coded in Python utilizing the KERAS library leveraging a Tensor-Flow backend with GPU utilization.
An output image size of 256x256 pixels was selected in order to optimize training time while still having a minimum viable output for artistic prints. Training of the networks took several days to complete over 300,000 epochs with a batch size of 16. Again, hyperparameters such as learning rate, batch size, and layer structure were not changed as the initial setup produced the desired results.
Results
Since the stated goal of this project was based on artistic subjectivity, traditional measures such as accuracy and error rate do not provide meaningful insights into its success. The model produced acceptable outputs and therefore achieved the intended goal of the work. The images produced were interesting and visually appealing enough and therefore there was no need to continue training or tuning the model.



It should be stated, however, that a layer of human-selection was still required in order to produce these results. While all the images were produced from an initial random vector, many of them resulted in less-than-acceptable levels of variety (due to mode collapse) or visual interest.
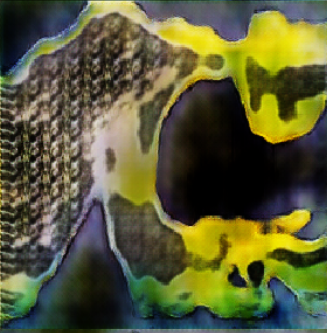


Perhaps with additional tuning and refining, these issues could be reduced, but it was not necessary under these particular circumstances. This should always be considered when judging the effectiveness of a GAN; it should not be judged on the most realistic images produced but on the complete spectrum of the population. It is easy to gravitate towards the most successful results while ignoring the many results that are clearly unrealistic, but it introduces a level of human-bias to the machine-learning that would not be possible in a fully automated application.
These images are now part of an art installation. Twelve of the most pleasing resulting images were selected for prints.

Additionally, one image was selected as the subject of a 48-inch x 48-inch acrylic painting.
