Image Recognition For Specialty Produce

Overview
Specialty Produce has one of the most extensive databases of information surrounding produce. In order to fully leverage all of this information in the most advanced way possible, a project was started to perform image classification based on each of their products. The most prohibitive portion of most image recognition is not computation power, but labeled data collection. Specialty Produce is in the unique circumstance to have ready access to thousands of products. This is a highly valuable asset that is difficult with which to compete. The largest hurdle is simply collecting the variety of images and have them properly labelled. Through hardware development and digital data augmentation this hurdle was overcome.
Approach
Image recognition requires labeled images of “real-world” examples for each class. If the image recognition is in a restricted environment like a laboratory or machine line, the image surrounding the object is less important to introduce maximum variance. However, given that the end-state of this product will be user-submitted images, the images need to be as diverse as possible. Rather than attempting to recreate these settings in real-world environments, data is collected in as uniform of environments as possible and then introduce this variation digitally. Currently, the PoC is only classifying bananas by ripeness (i.e. days to being overripe)
Hardware
There are 5 main components to the hardware:
- Computer (Raspberry Pi)
- Camera module
- Spinning platform
- Photo box
- RFID chip reader

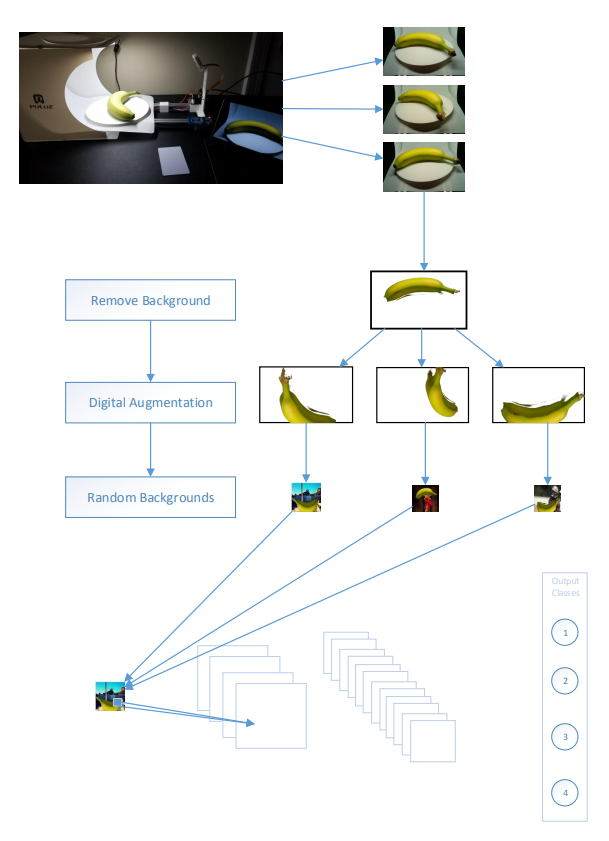
The computer is connected to a camera and spinning platform that capture numerous images of the product from different angles. This not only ensures maximum information gain, but also naturally balances the variation within each class. The photo box provides a uniform background which makes it easy to remove during pre-processing. In order to fully streamline the process and ensure as few misclassifications as possible, RFID tags are assigned to each product. After the item is placed on the platform, the corresponding card is tapped. The product ID is captured from the card, the photos are taken, and each image is stored in a database. A single product can be scanned in as little as 15 seconds with essentially no input from the user other than the card tap.
Software
The data capture code, image processing, and the neural network are written in Python.
Data Capture
The code relies on several python hardware libraries to interface with the camera, stepper motor, and RFID tag, in addition to file system and SQL database packages to store the information. The number of images per full-rotation can be selected; however, there are diminishing returns as the images might not have enough variation if more are selected and the capture time will increase. Encoding of the RFID tags is handled separately.
Image Processing
There are 3 steps to the pre-processing before they can be consumed by the model:
- Remove Background: the background of the image must be removed otherwise when the model sees a real-world image, it will be confused because it does not look like the photo box
- Digital Augmentation: by stretching, skewing, and otherwise altering the original, we can produce multiple images from one. This step accomplishes two things. The first is that it allows for various real-world variances to be introduced. Images will not have the same lighting conditions, angles, item placement, or color balance as the captured data so this is all introduced artificially. The second is that it allows for multiple training images to be produced from a single image.
- Random Backgrounds: the images are added on top of random backgrounds to simulate the variety of real-world images that will eventually be processed by the production model. This helps train the model to ignore everything but the original item. This is also where the image is resized to fit the model
Neural Network
The network was coded directly in TensorFlow. Transfer learning pretrained on ImageNet was utilized in order to expedite learning. Currently, the PoC is only classifying bananas by ripeness (i.e. days to being overripe) and has not been properly tuned. Once a larger set of the final data set has been collected, hyperparameter tuning will be performed more thoroughly.
End-State
A twitter app has already been developed, allowing the model to run on an image tweeted to a specific account. After the model has run, it retweets with a model score. Eventually, this project will be incorporated into the Specialty Produce mobile app.